Open Refine tutorial: How to calculate facet aggregates
OpenRefine continues to be an excellent interactive data cleaning tool. After using it for a few years, I continue to learn new ways that it can be used. I recently learnt how to emulate the SQL grouping functionality. I’ll go through the steps below using a simple contrived dataset that I created. The dataset has four columns, City, PropertyID, value, size.
If this table were in a relational database, I could ask the following questions:
- What is the total value of all property in a specific city?
- What is the average square metre value in each city?
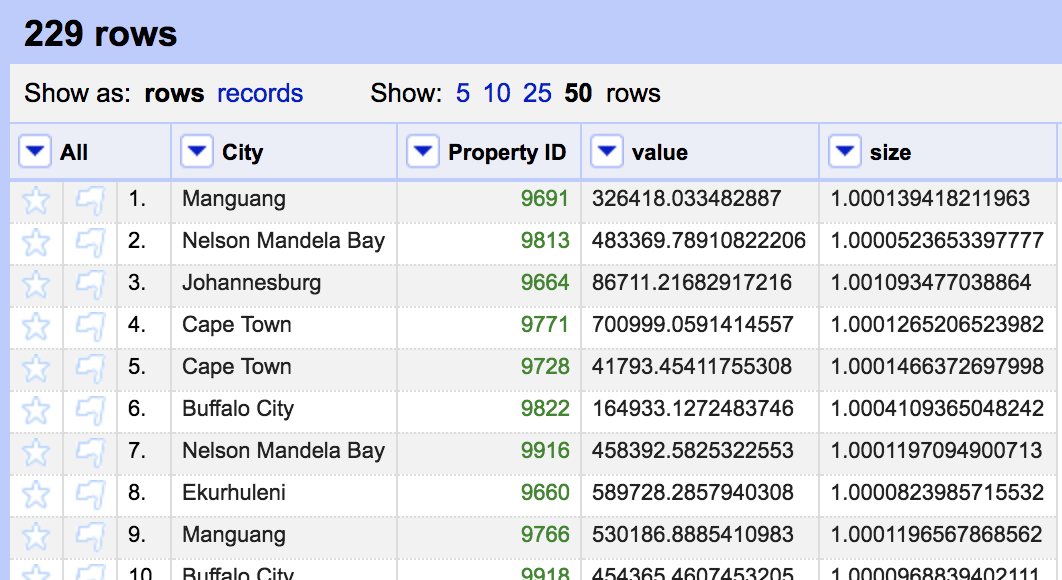
The first step to calculating the total value of property per city is to sort all the rows by the city name.
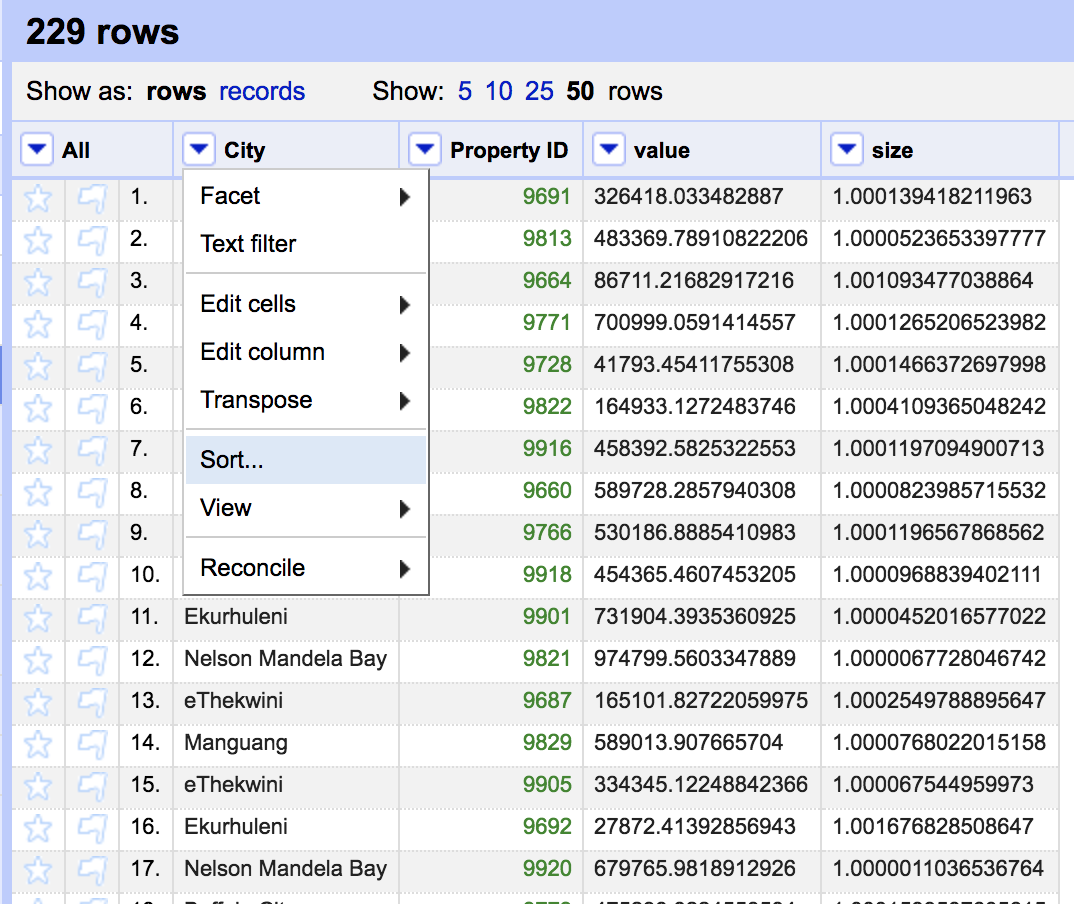
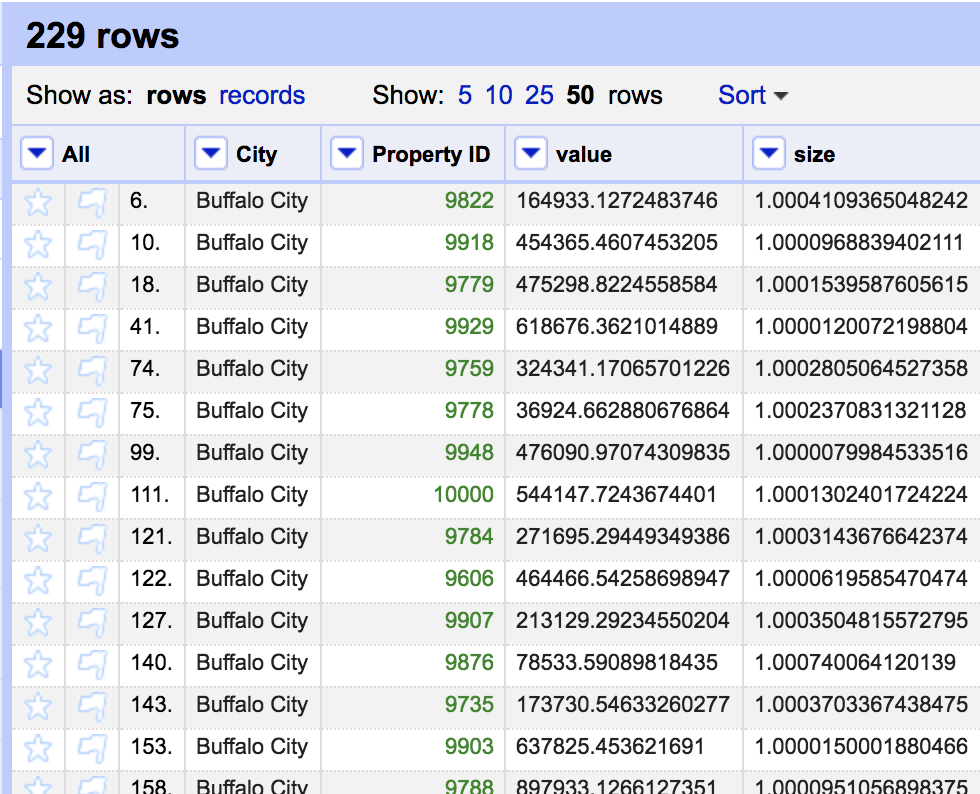
Simply sorting gives us a view of the data. The underlying dataset has not yet been sorted. We need to change the underlying order before moving onto the next step. At the top of the screen you will see an option for permanently reording the dataset.
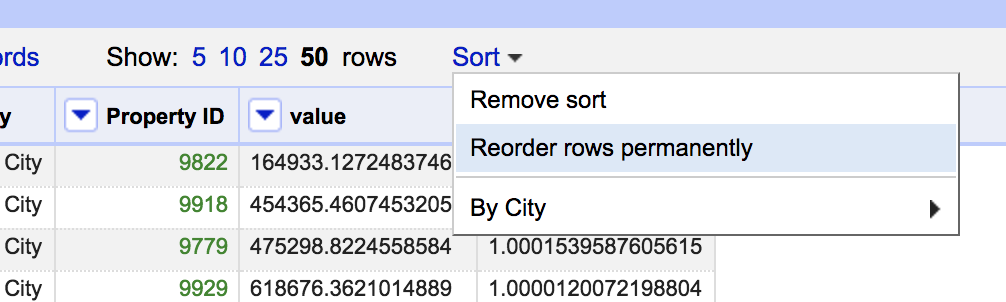
This now sets us up to convert the rows into records. You will notice two links at the top of the screen named rows and records. Rows is currently selected, showing 229 separate rows. Records represent multi-row values. A record is defined by a group of sequential sorted rows where the first column contains a single value, followed by a number of rows with blank values in the first column. To achieve this we use the blank down function.

Now select the record function.
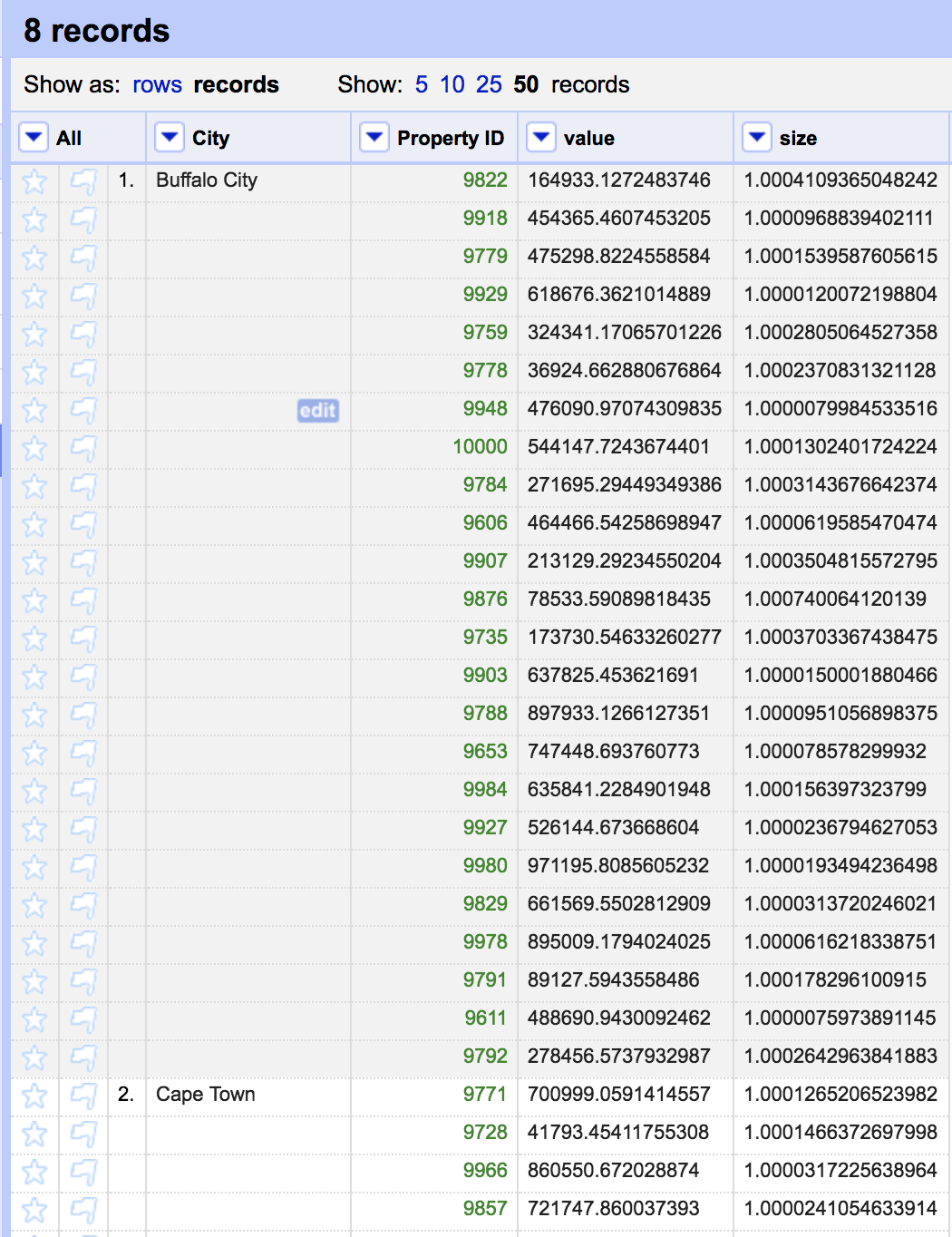
We now have only 8 records, one per city. Buffalo City for example is a single record with 24 rows.
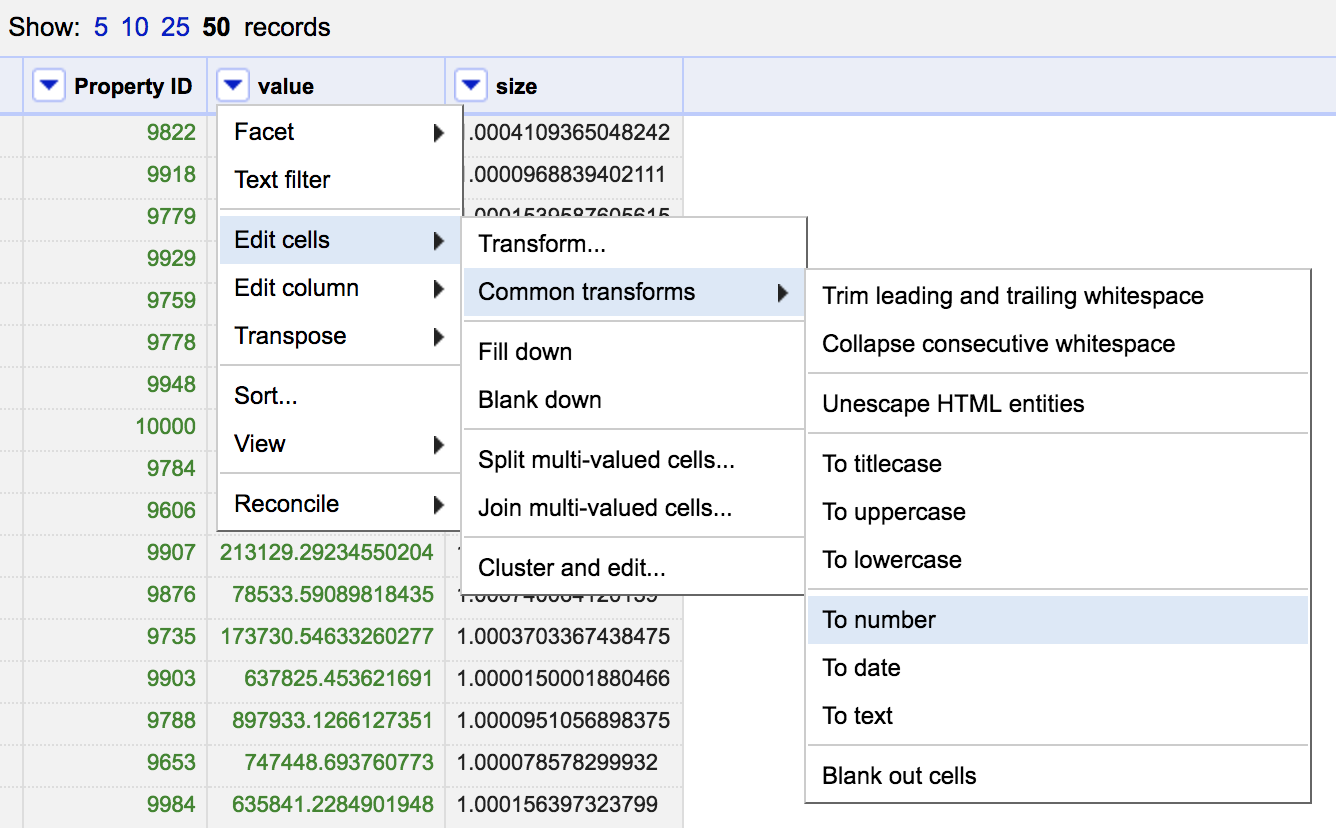
We can now apply functions to all of the values in this record. To calculate the total value we first make sure that our value column is a number (it is stored as text by default).
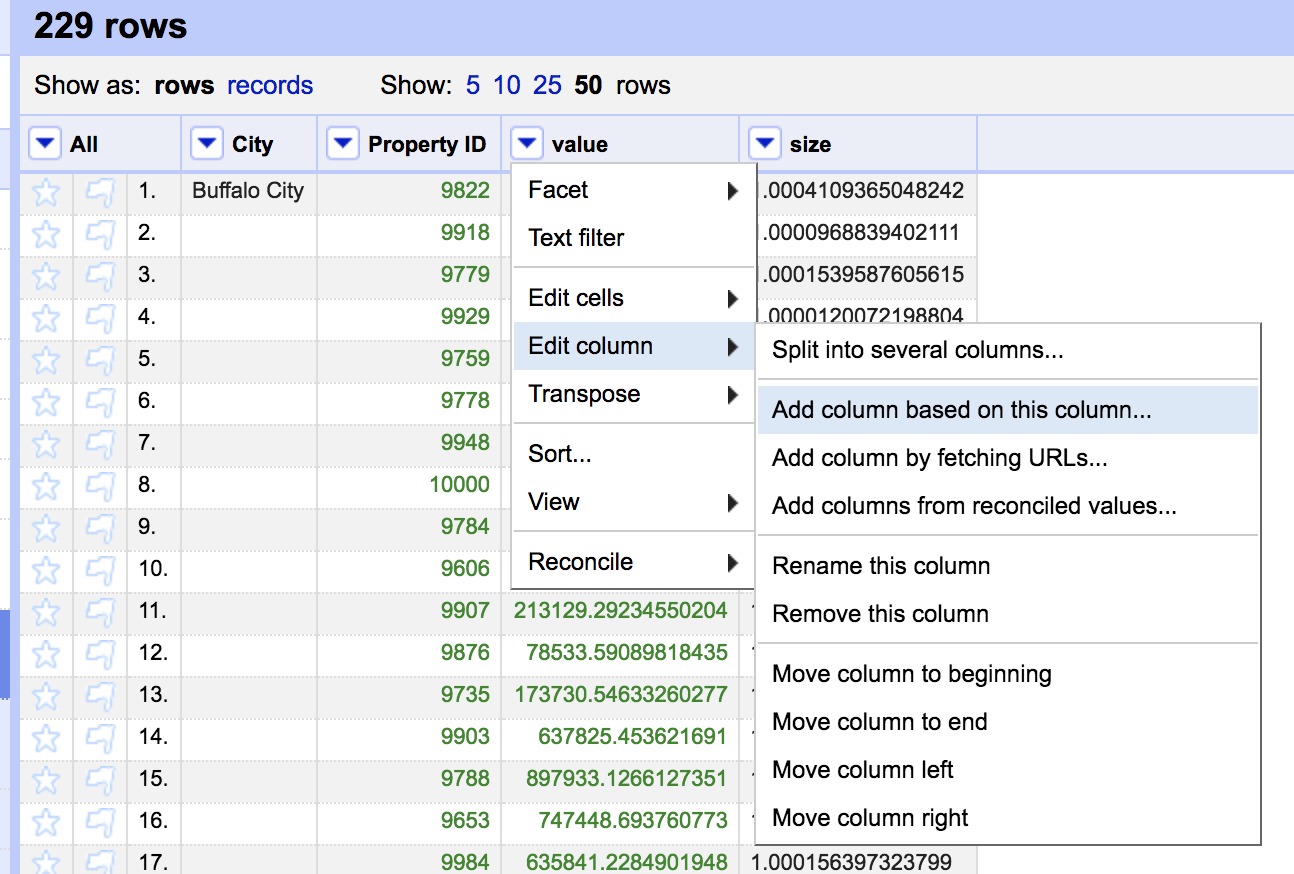
Then create a new column and calculate the sum of all the value cells in that record.
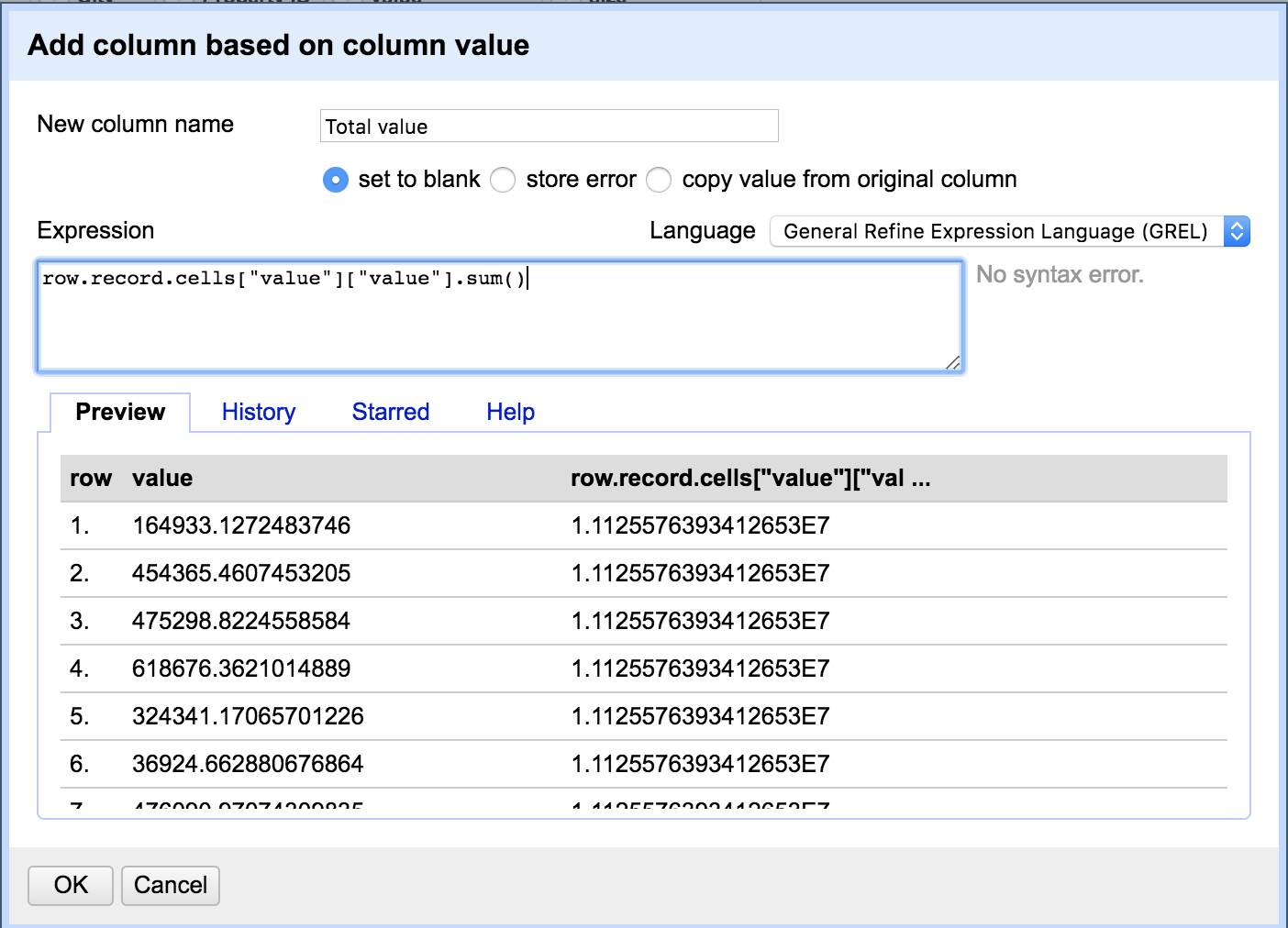
This column now contains the total value that we want.
We can now remove the old value column
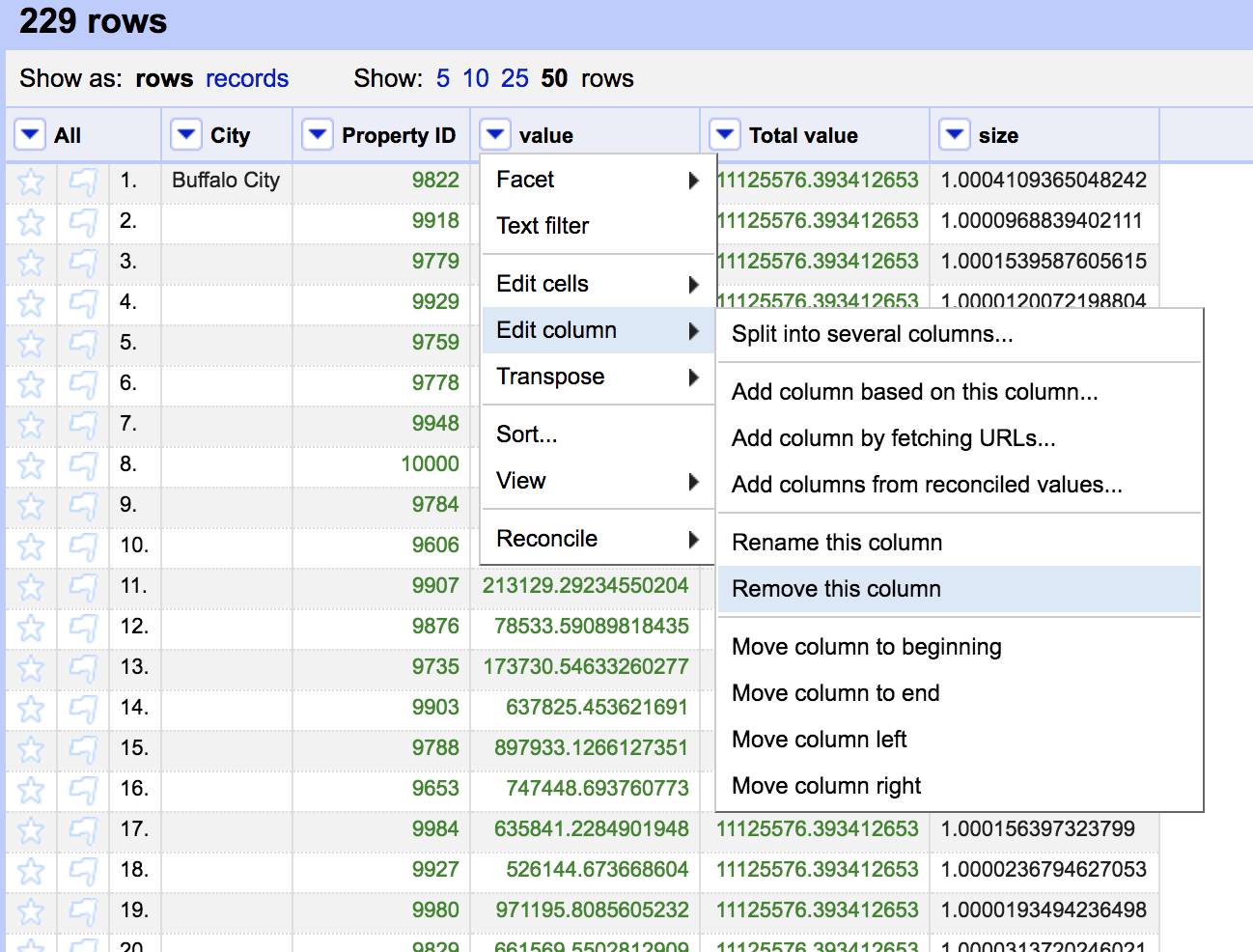
Unfortunately it is duplicated a number of times per record. We can easily remove the duplicates by changing back to rows and faceting the City column by blanks and select only the blank rows.

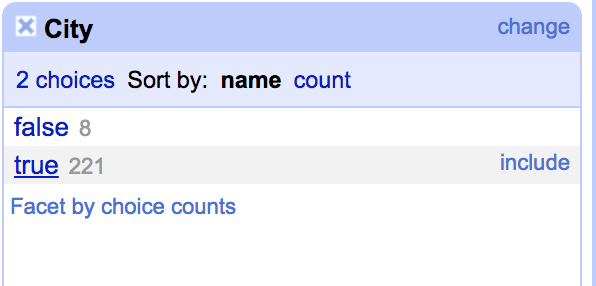
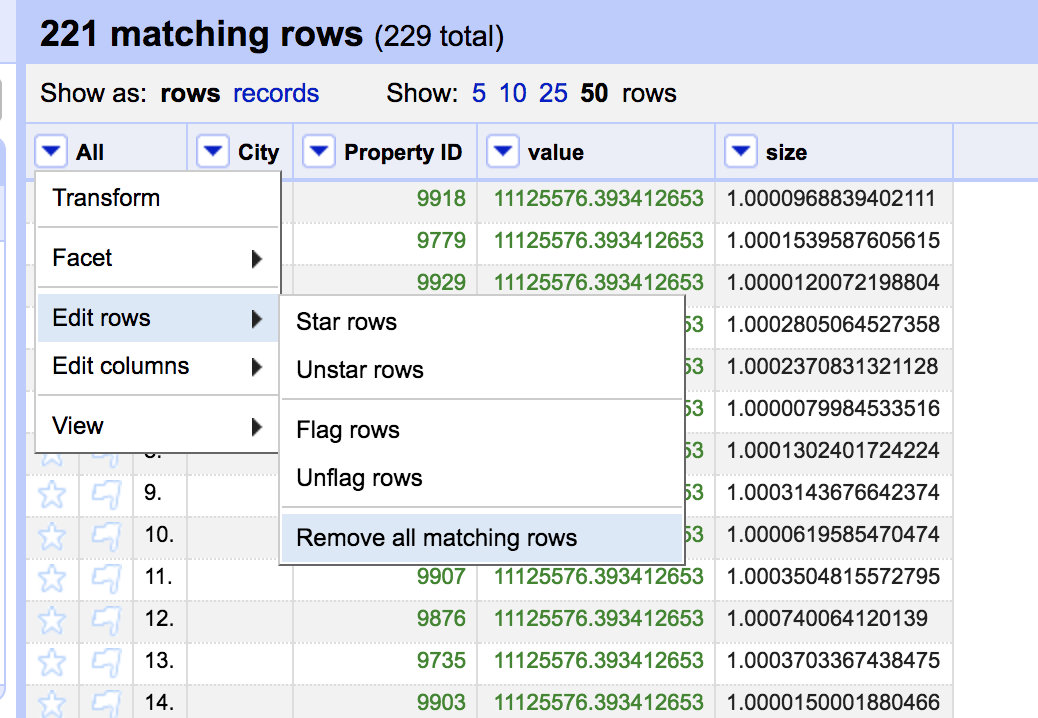
Remove all the matching rows and reset the facet
and voilà
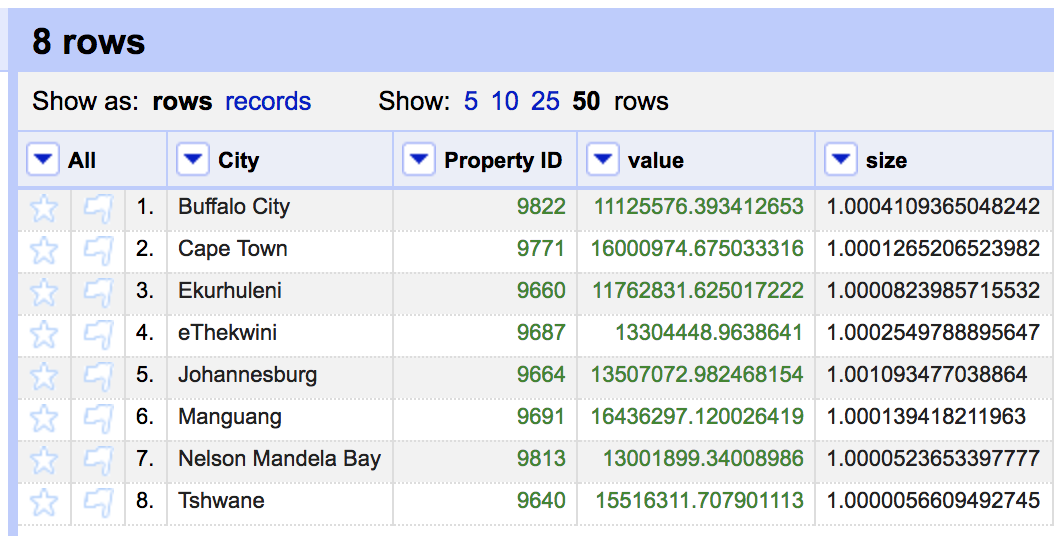
This technique is quite useful for cleaning duplicate rows in general. I hope this brief tutorial is valuable to someone.












