This is a short, practical, Python tutorial on using the Twitter API to get all the Tweets from a public Twitter account in CSV and JSON formats. You can then do some data science on the Tweets in your favourite analysis tool.
I will be using the terminal in macOS but this will work just as well on Windows or any flavour of Linux (e.g. Ubuntu.)
For your setup you will need:
- Python 3
- Your favourite text editor
- The handle of a public Twitter account
- Your own Twitter developer account
Before you get coding you need to register a project or "application" with Twitter and get an API key and secret. This is free and usually automatically approved instantly. Head on over to https://bit.ly/OpenUpTwitter1 and come back with those details. Twitter only show the details once so be sure to copy them down safely. If you forget them you will need to regenerate the key and secret and copy them again. For read only access to public Twitter data you don’t need to generate OAuth tokens.
Now we can get to Twittering. Tweepy is a fantastic Python library for working with the Twitter API. You can go directly to the Twitter API over HTTP with Python requests but we won’t cover that today. In your terminal run:
Let’s do a quick test by entering the Python interpreter (just run python in your terminal.)
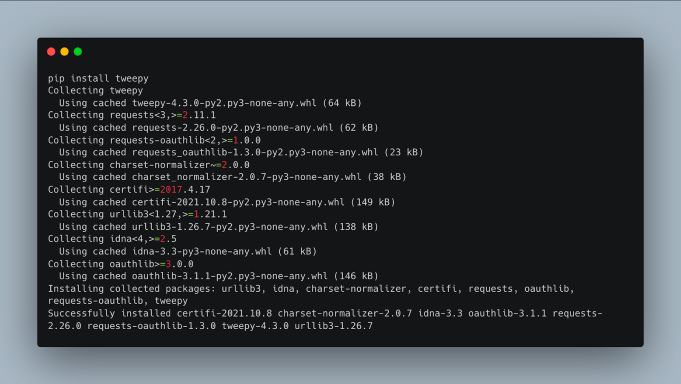
Then let’s authenticate using your keys:
Step 3: Make a request to the Twitter API
Now get an api instance:
And finally we can get some Tweets:
You should see the text of a few Tweets. Don’t try this too many times as Twitter does rate limit most API calls. If you hit the rate limit you’ll need to wait 15 minutes for the next window. Great so you’ve tested your API keys and seen a few Tweets.
Step 4: Get all the Tweets from a public Twitter account and save them to CSV and JSON.
To do that we need to use the cursor method which essentially pages through available Tweets.
Let's make a directory called get-tweets and then make a file inside it named main.py with the following contents:
Now, making sure you have the API_KEY and API_SECRET environment variables set, you should be able to run it with python main.py.
And within a few minutes you’ll see all Tweets from the NPA Tweets account. The Tweepy Cursor makes working with pagination and rate limits really simple. The Cursor method can be used with different Twitter API methods and so you can keep your code clean.
Now we know we can get all the Tweets, we want to save them to CSV and JSON files.
Saving the tweets as a JSON file
JSON first as it is the simplest, Tweepy already gives you the JSON object via _json and we can just append it to a file.
First import the json library at the top of your main.py:
Then initialise a json array:
Append each tweet to the array inside the loop:
And finally write the array out to a file on disk:
Run the code, python main.py, and soon you’ll have a tweets.json file with the details of each Tweet.
Saving the tweets as a CSV file
CSV lets you pick out the data you really want from the complex Tweet objects and is easier to read, so let’s get that working. Import the csv library at the top of main.py:
Initialise an array with the first index containing the column headings:
Then append the relevant fields to the array in the loop. Now if you run python main.py you should get a new tweets.csv file;
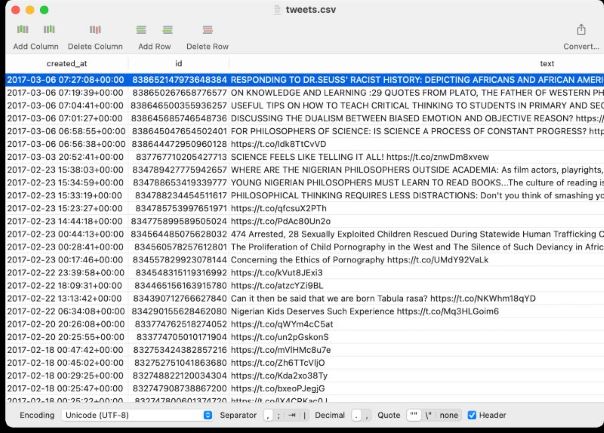
And that’s it, we’ve got our Tweets in two useful data formats and we can now analyse it for relationships, keywords, or anything else you might have in mind.
Hopefully this blog post can serve as a starting point for working with both Twitter Data and the Twitter API.











